Cloud-native Python from a Spring Developer Perspective
When a client asked for microservices written in Python, instead of the Spring Cloud ecosystem that I’m accustomed to, it was an adjustment. The task at hand was to replace an aging desktop application used by several hundred support staff with a simple, web-based application written in a programming language that the team knew. The original developers are no longer around, and the application is out of date. It has become challenging to install and maintain, and the list of bugs and needed enhancements grew too large for the client to ignore any longer. The client wanted a new tool that was faster, more reliable, had more features and was easier to support.
These are my key takeaways from this microservices project:
- Good microservice design transcends programming languages.
- REST and ORM libraries written in different languages are easy to transition between for experienced developers.
- JOSE (Javascript Object Signing and Encryption) simplifies securing a resource service.
- NATS is a simpler alternative to messaging services like RabbitMQ.
During design, we chose microservice boundaries that aligned with the application’s backing services. This system aggregates data from several LDAP and MSSQL sources, so we built a microservice for each of them. We could have created fine-grained microservices for individual domain contexts, like a facility service, audit service, keywords service, etc. Given the project budget and the type of application we were replacing, one microservice per backend made the most business sense.
Aside from the syntactical differences between Java and Python, the overall project semantics felt familiar, making for an easy transition. This table shows the Python libraries used in the project next to the equivalent Spring library:
| Spring | Python |
|---|---|
| Spring Data JPA | SQLAlchemy |
| Spring REST Docs | Hand-coded Swagger YAML files |
| Spring LDAP | LDAP3 |
| Spring Security Resource Service | Python JOSE |
| Spring Web MVC | Python Flask |
Python libraries exist that generate Swagger files, but we didn’t have time to add them. We loaded the Swagger file into ng OpenAPI Gen to generate the Angular API clients, something I never tried before. I recommend it because the generated client saves development time, reduces errors by implementing the API contract from the Swagger file, and speeds development by making auto-complete available for the method signatures and data types specified in the Swagger file.
The client uses Ping Identity for single-sign-on, so we didn’t have to worry about standing up an authentication service. We built a simple Security microservice to interface with Ping Identity. The frontend redirects the user to Ping Identity to do OpenID Connect authentication. The authorization code returned by Ping Identity is then posted to the Security microservice to exchange with Ping Identity for an access token.
Instead of setting up the API Gateway as an OAuth2 Resource Service using Spring Security, we use Python JOSE to verify the access token. The frontend caches the access token and passes it in the Authorization header to API Gateway REST endpoints. The Security microservice takes the access token, along with the JWT signing key, and calls the Python JOSE “decode” method to confirm the access token’s authenticity. This approach to token verification works much faster than calling the Ping Identity token introspection endpoint for validation.
As far as not having Spring Discovery and Spring Configuration, Kubernetes Services and Namespaces work just as well. Load balanced Kubernetes Services allow the client to scale microservices up and down, and the Service load balancer knows when instances get added or removed. The microservice does not need to register with a discovery service at startup.
Using separate Kubernetes namespaces for the development and production environments eliminated the need for a configuration service. The release pipeline supplies the appropriate variables and secrets for a given target namespace. Also, namespaces allow us to reuse the Kubernetes Service URLs in both environments, so the API Gateway calls the same backend Service URLs in development as it does in production.
System ingress from the client’s Intranet is only allowed into Nginx, which hosts front-end resources and the API Gateway service. The backend services connect to a separate subnet to which only the API Gateway has access. The backend services can all communicate with NATS, used for the event-driven design, which connects to the same subnet.
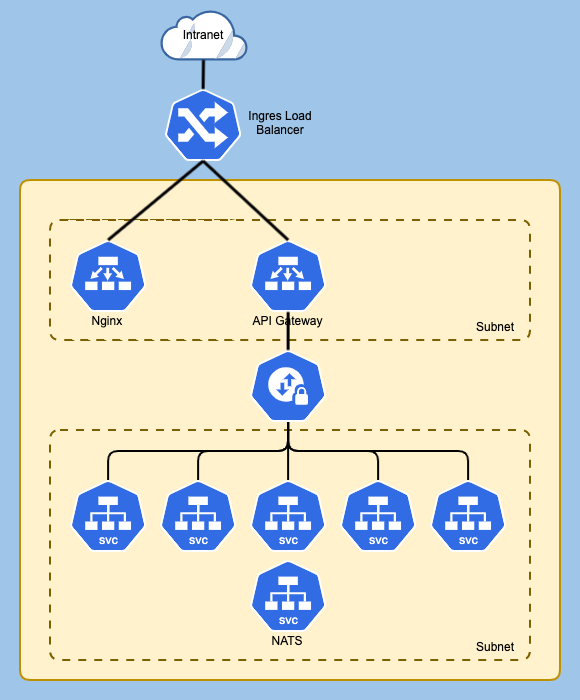
The NATS messaging service took minimal work to configure, making it easy to get going with the event-driven design. The original desktop application had a delay while it logged user actions. With the new system, publishing user actions to NATS is fast, and the time it takes to write the event to the audit log occurs in the background. Also, changing LDAP data is slow in the desktop application. The client is thrilled with the new asynchronous design for LDAP changes. Users get a sub-second response time when they publish change requests to NATS and continue working while the updates occur behind the scenes.
One thing we didn’t get to is a distributed cache. Many auto-completed input fields and lists use infrequently changed LDAP data, such as facilities, departments, positions, and job roles. The web interface would be snappier if it used an in-memory cache, like Redis.
Overall, the project was a success, thanks in large part to my teammates at Ahead. We delivered the simplified, microservice solution that the client asked for written in the client’s preferred programming language. The client no longer has to support a desktop application. The bugs are gone, and users got the enhancements they wanted. Best of all, thanks to the event-driven design, the users aren’t stuck waiting and waiting for LDAP updates to complete.